Data Preparation
Dataframes Before Transforming
Before processing Clustering analysis, it is necessary to extract the data required for Clustering analysis from the previously cleaned datasets (Players Datasets & Clubs Dataset) and combine the extracted data in a dataframe. It can be used for analysis. The figure below shows what the two datasets looked like before they were extracted and merged.
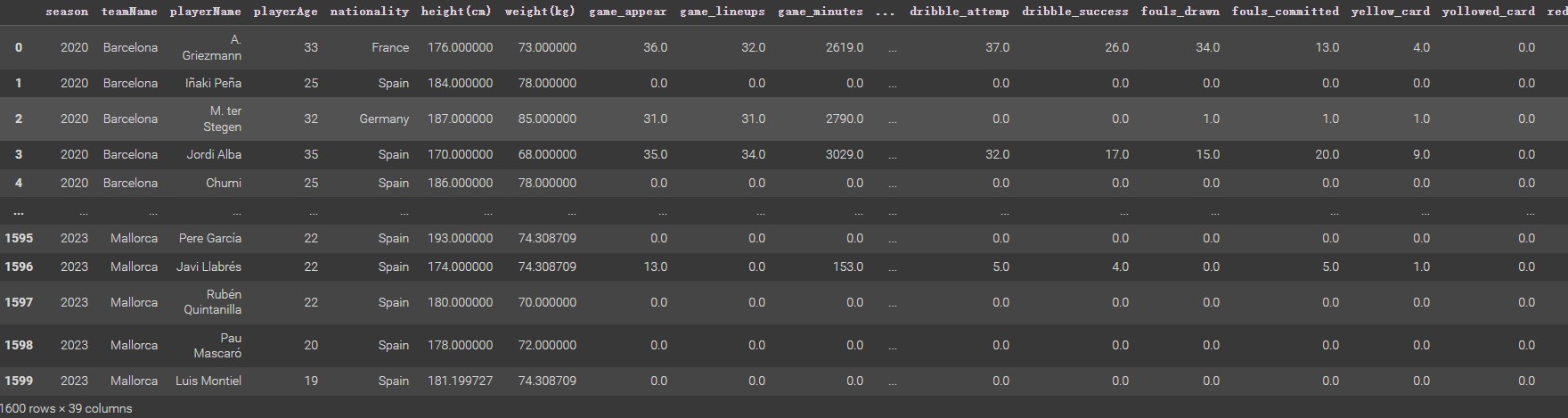
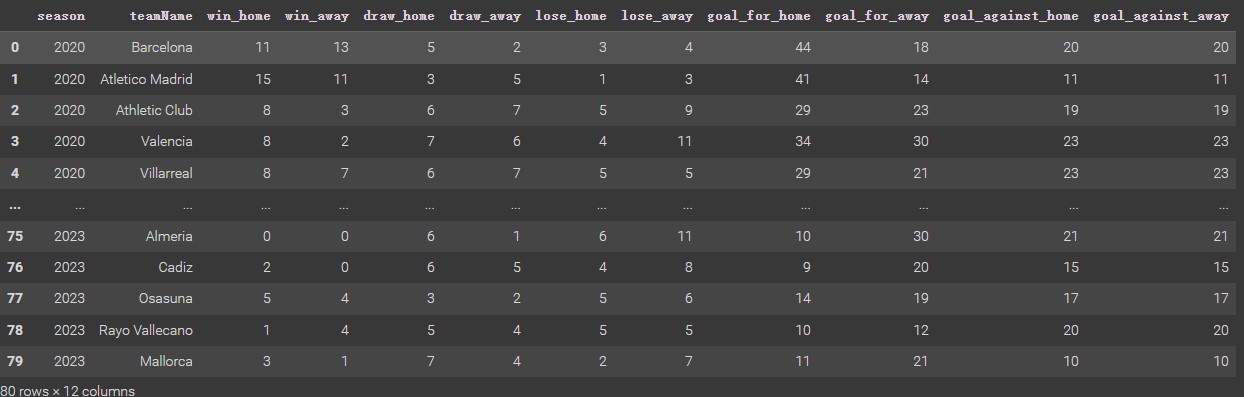
This clustering analysis just focuses on the relationship between players’ shooting quality and the team’s performance(Clusetring Plan). Therefore, Extracting the variables: teanName, playerName, position, shots_total,shots_on, and goals_total from the player dataset. The main reason for needing position variables is to drop the goalkeepers’ data because the goalkeepers are not involved in the attack or shooting for a game. Players in this position do not need to be considered in the analysis. For the clubs’ dataset, after calculating the points for each club per season and generating a new column called PTS(3 Points for a win, 1 Point for a draw, and 0 points for a loss), all extracted data can be combined into a data frame and ready for next step.
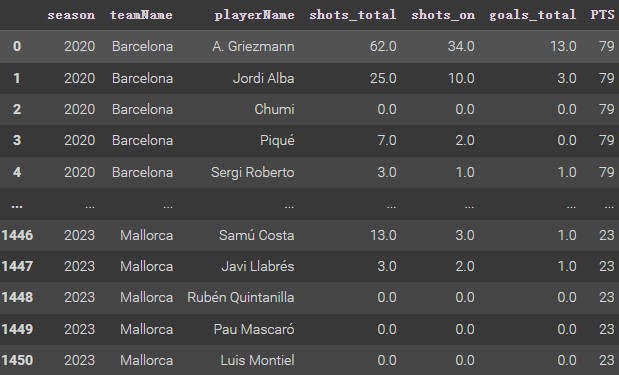
DataFrame After Transforming
According to the above Merge Dataframe, picking shots_total, shots_on, and goal_total as eigenvalue for this clustering analysis. These three variables are both unlabeled numeric data and are suitable for processing clustering analysis.
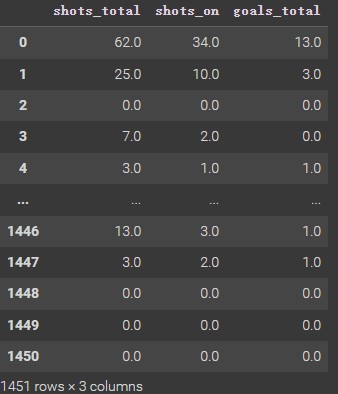
After that, it may use following code to transform and scale these data and get ready to implement clustering algorithms.
X = clustering_df[['shots_total','shots_on','goals_total']]
scaler = StandardScaler()
scale_X = scaler.fit_transform(X)
After finishing the clustering analysis, other variables in the merged dataframe will be used for in-depth explore the relationship between players’ shooting quality and the team’s performance.
